Symulacja procesów
Symulacja procesów pozwala zbadać procesy biznesowe i ustalić, jaki byłby czas ich wykonania, koszty oraz wymagania względem zasobów. Symulacja może być wykorzystana do przeanalizowania różnic pomiędzy poszczególnymi wariantami procesów, w celu określenia najkorzystniejszej wersji dla implementacji. Tym samym, symulacja procesów pomaga ocenić i określić liczbę potrzebnych usprawnień. Symulacja jest więc istotnym narzędziem analizy i optymalizacji procesów.
Dla jakich typów modeli jest dostępna symulacja procesów?
Symulacja procesów jest dostępna dla Diagramów procesów biznesowych.
Gdzie mogę skonfigurować dane, w oparciu o które wykona się symulacja?
Standardowo, atrybuty wykorzystywane przez mechanizmy symulacji procesów można znaleźć w zakładce „Dane symulacyjne”.
Czego potrzebuję, aby móc rozpocząć?
Aby wykonać symulację procesu biznesowego, która przedstawi znaczące wyniki, należy zdefiniować co najmniej następujące dane symulacyjne:
Czas wykonania dla wszystkich Zadań.
Prawdopodobieństwo dla wszystkich ścieżek alternatywnych wychodzących z Bramki wykluczającej. Prawdopodobieństwo to podaje się w atrybucie Warunek przejścia dla relacji Kolejny (ang. Sequence flow).
WskazówkaW najprostszej formie warunki przejścia mogą być liczbami zmiennoprzecinkowymi
≥0 i≤1 (np. 0.7). Suma prawdopodobieństw wszystkich ścieżek wychodzących z bramki musi się równać 1.
Jak mogę wykonać analizę kosztów osobowych?
Aby wykonać analizę kosztów osobowych, potrzebne jest zdefiniowanie odpowiedzialnych ról oraz powiązanie ich z procesami biznesowymi:
Do każdego Zadania, przypisz odpowiednią Rolę w atrybucie Odpowiedzialny za wykonanie (rozdział Notatnika "RACI").
Uzupełnij atrybut Stawka godzinowa, aby określić przeciętne wynagrodzenie pracowników wykonujących daną Rolę.
Podaj dodatkowe nieosobowe Koszty, które wiążą się z wykonaniem poszczególnych Zadań.
W jaki sposób symulacja procesów pomaga planować wydajność?
Na potrzeby planowania wydajności należy zdefiniować częstotliwość wykonywania procesu:
- Dla Zdarzenia początkowego, podaj Ilość/częstotliwość (=liczbę wystąpień) danego procesu w podanym Okresie.
Podane powyżej atrybuty to tylko zestaw minimalny. W dalszej sekcji bardziej szczegółowo opisane są atrybuty wymagane do symulacji procesów.
Symulacja procesów jest dostępna tylko w ADONIS NP Enterprise Edition. Dostępność tej opcji zależy od posiadanej licencji i biblioteki aplikacji. Wszystkie przykłady i opisy w poniższym rozdziale odnoszą się do biblioteki aplikacji ADONIS BPMS.
W razie zainteresowania prostszym rozwiązaniem niż symulacja procesów, polecamy skorzystanie z opcji process stepper, która zapewnia przegląd konkretnych ścieżek procesu.
Przygotowanie modelu do symulacji
Istnieją pewne wymagania, które muszą być spełnione, zanim symulacja procesu biznesowego zostanie wykonana. Wymagania te można podzielić na dwie kategorie:
Wymagania odnośnie struktury modelu
Wymagania odnośnie atrybutów
Dalsza część dokumentu zawiera więcej informacji na temat tych wymagań.
Zdarzenia początkowe
Zdarzenie początkowe wskazuje powód rozpoczęcia konkretnego procesu.

Wymagania dotyczące struktury modelu
- Zaleca się, by każdy Diagram procesów biznesowych zawierał dokładnie jeden obiekt typu Zdarzenie początkowe, który symbolizuje początek procesu:
Wymagania dotyczące atrybutów
- Aby pokazać, jak często proces jest wykonywany, należy uzupełnić atrybuty Ilość/Częstotliwość i Okres. Jeśli atrybut Ilość/Częstotliwość jest pusty, symulacja przyjmie wartość domyślną "100". Wartość domyślna atrybutu Okres to "rocznie".
Przykład
Jeśli chcesz określić, że proces jest wykonywany 100 razy dziennie. Ustaw Ilość/Częstotliwość na "100" i Okres na "dziennie".
Zadania
Zadania są aktywnościami w ramach przepływu procesu. Zadania mogą mieć przypisane koszty i czasy. Jeśli są wykonywane przez pracowników, można również uwzględnić koszty osobowe (więcej informacji na ten temat zawiera punkt Role).

Wymagania dotyczące struktury modelu
- Zadania powinny być częścią przepływu procesu.
Wymagania dotyczące atrybutów
Aby podać, jak długo trwa wykonanie poszczególnego Zadania, skorzystaj z atrybutu Czas wykonania. Czas oczekiwania pozwala podać, ile czasu upływa przed rozpoczęciem pracy, zaś Czas magazynowania i Czas transportu pokazują opóźnienia, które mają miejsce po tym jak Zadanie zostało wykonane.
Aby podać, że wykonanie Zadania generuje koszty, użyj atrybutu Koszty.
Możesz też przypisać jedną lub wiele Ról do Zadania w atrybucie Odpowiedzialny za wykonanie (rozdział "Diagram organizacji (RACI)"). Jeśli podasz dwie Role lub więcej, na potrzeby symulacji zostanie przyjęte, że wszystkie z nich są konieczne do wykonania Zadania.
Przykład
Chcesz podać, że Zadanie można wykonać w ciągu 10 minut. Nie ma czasu oczekiwania, magazynowania i transportu, ani kosztów. Ustaw Czas wykonania na "10 minut".
Podprocesy
Podproces to aktywność reprezentująca proces niższego poziomu. Pozwala na szczegółowe opisanie części procesu w powiązanym podmodelu.

Symulacja nie wspiera modelowania podprocesów z treścią w ramach głównego modelu (modelowanie "inline"). Dotyczy to również Podprocesów "ad hoc".
Wymagania dotyczące struktury modelu
- Aby dodać do obiektu Podproces referencję do Diagramu Procesów Biznesowych, skorzystaj z atrybutu Podproces (rozdział "Informacje ogólne"). Powiązany podmodel zostanie również uwzględniony w symulacji. Jeśli nie ma powiązanego modelu, dane liczbowe na potrzeby symulacji można podać bezpośrednio w obiekcie Podproces.
Wymagania dotyczące atrybutów
Z założenia wszystkie atrybuty powinny być wyliczane w oparciu o analizę modeli niższego rzędu, więc jedynym wymaganiem jest uzupełnienie atrybutu Podproces o referencję.
Jeżeli jednak nie ma powiązanego modelu niższego rzędu, albo też powinny być zastosowane inne wartości, na poziomie Podprocesu należy zaznaczyć opcję Przypisz zagregowane wartości do podprocesu. W tym wypadku dane symulacyjne muszą zostać zdefiniowane w Podprocesie (zobacz Zadania, aby dowiedzieć się więcej o wymaganych atrybutach).
Bramki wykluczające i przepływy procesu
Bramka wykluczająca pozwala opisać ścieżki alternatywne, z których tylko jedna może być wybrana w procesie.

Wymagania dotyczące struktury modelu
- Rozdzielanie ścieżek procesu z wykorzystaniem Bramek wykluczających, a nie Przepływów warunkowych.
Wymagania dotyczące atrybutów
Aby zdefiniować prawdopodobieństwo ścieżki wychodzącej z Bramki wykluczającej, należy uzupełnić atrybut Warunek przejścia dla każdej z relacji Kolejny.
W najprostszej formie warunki przejścia mogą być liczbami zmiennoprzecinkowymi
≥0 i≤1 (np. 0.7).
Suma prawdopodobieństw dla wychodzących ścieżek musi być równa 1. Jeżeli nie ma zdefiniowanych żadnych prawdopodobieństw, zakłada się, że wszystkie ścieżki wykonywane są z tym samym prawdopodobieństwem (np. 50/50 dla 2 wychodzących ścieżek). Jeżeli prawdopodobieństwa zdefiniowane są dla niektórych ścieżek, mechanizm symulacji obliczy liczbę prawdopodobieństw wszystkich ścieżek brakujących do 100% i rozdzieli je równo pomiędzy ścieżki bez zdefiniowanych prawdopodobieństw.
Przykład
Chcesz podać, że ścieżka "Klient indywidualny" jest wybierana w 80% przypadków, a ścieżka "Klient korporacyjny" w 20% przypadków. Ustaw Warunek przejścia na pierwszej relacji Kolejny na "0,8", a na kolejnej podaj "0,2".
Zaawansowane metody definiowania warunków przejścia
Opisany powyżej sposób przedstawiania warunków przejścia za pomocą liczb zmiennoprzecinkowych można rozpatrywać jako rozkład dyskretny.
Jeśli proces zawiera pętle, można użyć liczb zmiennoprzecinkowych, aby przypisać różne prawdopodobieństwa dla kolejnych wykonań pętli. Możesz dowiedzieć się więcej na ten temat w sekcji Ograniczenie liczby pętli.
Oprócz liczb zmiennoprzecinkowych, możesz również używać zmiennych w rozkładach dyskretnych. Można ich używać w różnych punktach procesu w celu zdefiniowania warunków przejścia. Możesz dowiedzieć się więcej na ten temat w sekcji Wybór ścieżki procesu w oparciu o prawdopodobieństwa zależne.
Oprócz rozkładu dyskretnego, system ADONIS obsługuje również różne typy rozkładów ciągłych: są to rozkład normalny, rozkład wykładniczy i rozkład jednostajny. Aby dowiedzieć się więcej o rozkładach prawdopodobieństwa, których można użyć do określenia prawdopodobieństwa ścieżek alternatywnych podczas symulacji procesu, zobacz Rozkład prawdopodobieństwa.
Bramki niewykluczające
Bramki niewykluczające pozwalają opisać sytuację, w której wiele ścieżek jest wykonywanych w tym samym czasie.

Wymagania dotyczące struktury modelu
- Ścieżki równoległe powinny być rozdzielane i łączone za pomocą Bramek niewykluczających zdefiniowanych jako Bramki równoległe (atrybut Typ bramki w rozdziale "Właściwości obiektu").
Mechanizm symulacji wspiera tylko Bramki równoległe dla symulacji zadań wykonywanych w tym samym
czasie. Bramki alternatywne
![]() traktowane są przez symulację jako
Bramki wykluczające .
traktowane są przez symulację jako
Bramki wykluczające .
Zdarzenia pośrednie
Zdarzenia pośrednie to zdarzenia, które dzieją się podczas trwania procesu.

BPMN 2.0 definiuje dwa główne rodzaje Zdarzeń pośrednich: 1. znajdujące się w ramach przepływu procesu oraz: 2. doczepione do krawędzi aktywności.
Zdarzenia pośrednie (przepływ procesu) są ignorowane przez symulację. Aby udokumentować opóźnienia w procesie wywołane np. oczekiwaniem na komunikat od zewnętrznego uczestnika (reprezentowanego przez inny basen), należy wykorzystać atrybut Czas oczekiwania w kolejnym Zadaniu.
Zdarzenia pośrednie (krawędź) pozwalają na pokazywanie, że pewne wydarzenia mogą wystąpić podczas wykonywania Zadania. Mogą być one przerywające albo nieprzerywające (atrybut Typ w rozdziale "Typ zdarzenia"):
Można dla nich zdefiniować: Jak prawdopodobne jest, że wystąpią podczas wykonywania Zadania (atrybut Prawdopodobieństwo wystąpienia).
Jeśli Zadanie zostało przerwane, to na jakim etapie zaawansowania pracy się to wydarzyło, tzn. jaki procent kosztów i czasu powinien zostać doliczony do wyników symulacji (atrybut Stopień wykonania czynności przy wystąpieniu zdarzenia).
Wymagania dotyczące struktury modelu
- Zdarzenia pośrednie (krawędź) muszą być dołączone do Zadania (atrybut Dołączone do w rozdziale Notatnika "Informacje ogólne").
Wymagania dotyczące atrybutów
- Należy dopasować Prawdopodobieństwo wystąpienia oraz Stopień wykonania czynności przy
wystąpieniu zdarzenia. Oba parametry zdefiniowane są przez liczby zmiennoprzecinkowe
≥0 i≤1 (np. 0.7). Jeśli nie zostaną uzupełnione, domyślna wartość obu tych atrybutów to "0,5".
Zdarzenia końcowe
Zdarzenia końcowe pokazują, jakimi rezultatami kończą się ścieżki procesu.

Wymagania dotyczące struktury modelu
- Aby możliwa była pogłębiona analiza wyników symulacji dla procesu, należy dla każdej ścieżki procesu zdefiniować Zdarzenie końcowe.
Role
Role definiują odpowiedzialności za Zadania. Są wykorzystywane do kalkulowania kosztów osobowych oraz zapotrzebowania na zasoby.

Wymagania dotyczące atrybutów
- Aby móc wyliczać koszty osobowe procesu, należy uzupełnić atrybut Stawka godzinowa.
Przykład
Chcesz sprecyzować, że wynagrodzenie pracownika pełniącego rolę "Opiekun klienta korporacyjnego" wynosi 50 PLN (waluta jest domniemana) na godzinę. Ustaw atrybut Stawka godzinowa na "50".
Wykonywanie symulacji
Aby wykonać symulację konkretnego modelu:
Otwórz model w edytorze graficznym.
Kliknij przycisk
 Więcej na
pasku menu modelu, wybierz Analiza procesu
Więcej na
pasku menu modelu, wybierz Analiza procesu
 i kliknij Symulacja.
i kliknij Symulacja.Zdefiniuj parametry symulacji:
W atrybucie Liczba wykonań symulacji podaj, ile razy system ADONIS ma przesymulować model.
W atrybucie Liczba dni pracy w roku zdefiniuj, ile dni roboczych w roku ma uwzględniać symulacja.
W atrybucie Liczba godzin pracy w dniu zdefiniuj, ile godzin w dniu roboczym ma uwzględniać symulacja.
WskazówkaIm większa jest Liczba wykonań symulacji, tym dokładniejsze są wyliczenia prawdopodobieństw wystąpienia poszczególnych ścieżek procesu, ale z kolei tym dłużej trzeba czekać na wyniki symulacji.
Liczba dni pracy w roku oraz Liczba godzin pracy w dniu są wykorzystywane do obliczenia zapotrzebowania na personel oraz właściwego grupowania wartości czasowych.
Liczba godzin pracy w dniu wyrażana jest w dziesiętnych godzinach (np. 7 godzin i 30 minut = 7.5).
Aby dowiedzieć się więcej, kliknij na ikony informacyjne
 znajdujące się obok atrybutów.
znajdujące się obok atrybutów.Kliknij Uruchom.
Zostaną uruchomione sprawdzenia, aby zweryfikować, czy model jest gotowy do symulacji. Wyniki sprawdzania pokazuje widżet "Sprawdzanie poprawności" widoczny z prawej strony okna programu.
Jeśli nie wystąpiły błędy, rozpocznie się generacja wyników symulacji. Gdy wyliczenia się zakończą, wyniki symulacji zostaną wyświetlone.
Porównywanie modeli stanu obecnego (AS-IS) oraz docelowego (TO-BE)
Oprócz symulowania konkretnego procesu można również bezpośrednio porównywać różne warianty procesów. Dzięki temu można testować zmiany i dopracowywać usprawnienia procesów. Aby uruchomić symulację wielu modeli:
Zaznacz dwa modele lub więcej w katalogu modeli.
Kliknij prawym klawiszem myszy na zaznaczenie, a następnie kliknij Symulacja.
Zaawansowane (różne godziny robocze i godziny pracy)
Wybierz tę opcję, jeżeli liczba godzin roboczych w organizacji i indywidualne godziny pracy są różne. Musisz zdefiniować następujące parametry symulacji:
W polu Dni robocze w roku (pracownik) wpisz średnią liczbę dni w roku, w których pracownik wykonuje pracę.
W polu Liczba godzin pracy w dniu wpisz średnią liczbę godzin w dniu, w których pracownik wykonuje pracę.
W polu Dni robocze w roku (organizacja) wpisz liczbę dni w roku, w których prowadzona jest działalność i wykonywane są procesy.
W polu Godziny pracy dziennie (organizacja) wpisz liczbę godzin w dniu, w których prowadzona jest działalność i wykonywane są procesy.
Przykład
Jeżeli organizacja działa non-stop (24/7/365), jeden dzień trwa 24 godziny i to ten czas powinien być wzięty pod uwagę podczas obliczania czasu cyklu procesu. Jednakże, czas pracy pracownika to typowo 8 godzin/dzień, co oznacza, że 24 godziny pracy organizacji to 3 dni pracy pracownika i to ten wynik jest brany pod uwagę podczas obliczania zapotrzebowania na personel.
Interpretowanie wyników symulacji
Po zakończeniu symulacji można zapoznać się z jej wynikami. Standardowo wyświetla się przegląd wyników symulacji. Dodatkowe zakładki dostarczają więcej informacji.
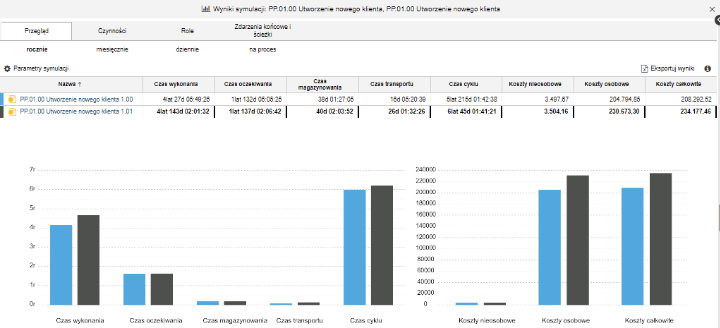
Dostępne są cztery następujące zakładki:
Przegląd: Przegląd wyników symulacji.
Czynności: Widok szczegółowy pozwalający zobaczyć, w jaki sposób poszczególne czynności przekładają się na koszty procesu. Wspiera Rachunek Kosztów Działań (ang. Activity-based Costing, ABC).
Obciążenie: Oszacowanie zapotrzebowania analizowanego procesu na personel. Jest to narzędzie kalkulacji wymagań co do etatów (FTE).
Zdarzenia końcowe i ścieżki: Analiza tego, które ścieżki prowadzą do jakich rezultatów procesu, oraz jak często występują. Pozwala na szczegółową analizę ścieżek procesu pod względem czasu i kosztów (niezbędne ścieżki, liczba ścieżek, kosztowne ścieżki, itp.). Możliwe jest też pokazanie ścieżek w sposób graficzny w modelu.
Typy rezultatów
Każda symulacja oferuje następujące wyniki (rozmieszczone w czterech zakładkach):
Czas wykonania: Jest to przeciętny czas potrzebny do wykonania konkretnej czynności.
Czas oczekiwania: Jest to oszacowanie przeciętnego czasu, jaki zajmuje oczekiwanie na moment wykonania czynności lub czasu, gdy czynności są przerwane.
Czas magazynowania: Jest to przeciętny czas, który upływa po zakończeniu wykonywania czynności, zanim proces przejdzie dalej.
Czas transportu: Jest to przeciętny czas potrzebny na transport między wykonaniem powiązanych ze sobą czynności.
Czas cyklu: Jest to średni czas od rozpoczęcia procesu do jego zakończenia (innymi słowy, czas odpowiedzi klientom na procesy związane z klientem).
Koszty nieosobowe: Są to koszty wykonywania konkretnych czynności, niezwiązane jednak z wynagrodzeniami wykonawców procesu.
Koszty osobowe: Koszty osobowe są wyliczane poprzez pomnożenie Czasu wykonania Zadań przez Stawkę godzinową przypisanych do nich Ról.
Przykład
Czas wykonania wszystkich Zadań w procesie "Szczegółowa kontrola bezpieczeństwa" to 15 minut (= ¼ godziny). Wynagrodzenie pracownika pełniącego rolę "Bezpieczeństwo lotniska" wynosi "20 PLN" (waluta jest domniemana) za godzinę. Całkowity koszt osobowy wynosi więc 5 PLN (¼x 20) za proces.
Koszty całkowite: Jest to suma kosztów nieosobowych i kosztów osobowych.
# wykonań: Jest to (przeciętna) liczba wykonań czynności.
Obciążenie: Jest to liczba pełnoetatowych pracowników pełniących daną rolę, potrzebna do wykonania czynności w wyznaczonym okresie. Wartość ta zakłada, że pracownik jest zaangażowany tylko w symulowany proces, bez dodatkowych obciążeń (zależnie od liczby godzin pracy w dniu).
Przykład
Proces "Szczegółowa kontrola bezpieczeństwa" jest wykonywany codziennie 20 razy. Czas wykonania wszystkich Zadań w procesie to 15 minut (= ¼ godziny). Liczba pełnoetatowych pracowników potrzebnych do wykonania procesu to zatem 0,7143 [(20 x ¼) : 7], przy założeniu, że została zachowana domyślna wartość "7" dla atrybutu Liczba godzin pracy w dniu.
Prawdopodobieństwo: Prawdopodobieństwo wystąpienia Zdarzenia końcowego w procentach (%).
Pokazywanie uśrednionych rezultatów rocznie, miesięcznie, dziennie lub na proces
Dla wszystkich zakładek z wynikami symulacji można analizować wyniki dla jednego procesu lub też wszystkich wykonań procesu w podanym okresie:
Aby wyświetlić przeciętne wyniki na proces, kliknij na opcję na proces.
Aby wyświetlić rezultaty dla wszystkich wykonań procesu kliknij odpowiednio na opcję rocznie, miesięcznie lub dziennie.
Przy wyliczaniu rezultatów dla wszystkich wykonań procesu uwzględniane są następujące elementy:
Atrybuty Zdarzenia początkowego: Ilość/częstość oraz Okres.
Parametry Liczba dni pracy w roku oraz Liczba godzin pracy w dniu, zdefiniowane przy uruchamianiu symulacji
Wybrany okres prezentacji wyników (rocznie, miesięcznie lub dziennie)
Przykład
Proces "Szczegółowa kontrola bezpieczeństwa" jest wykonywany codziennie 20 razy. Koszt osobowy procesu to 5 PLN. Całkowity koszt osobowy dziennie to 100 PLN (5 x 20). Całkowity koszt osobowy rocznie to 22000 (100 x 220), przy założeniu, że została zachowana domyślna wartość "220" dla atrybutu Liczba dni pracy w roku.
Przegląd
Ta zakładka zapewnia przegląd wyników symulacji. Wyniki są wyświetlane w następujący sposób:
Przeciętne wartości na proces lub dla wszystkich wykonań procesu w danym okresie są wyświetlane w tabeli. Tabela zawiera jeden wiersz dla każdego symulowanego procesu. Wyświetlane są następujące informacje:
Przeciętne czasy procesu.
Przeciętne koszty procesu.
Dodatkowo, najważniejsze wartości są prezentowane w formie graficznej pod tabelą:
Jeżeli symulujesz tylko jeden proces, dane pokazane są w formie wykresu kołowego.
Jeżeli symulujesz wiele modeli, kluczowe wartości prezentowane są w formie wykresu słupkowego. Jest to szczególnie przydatne dla porównywania modeli AS-IS oraz TO-BE, jako że pozwala łatwo zobaczyć, który wariant wypada korzystniej.
Zmiana parametrów symulacji
Aby zmienić parametry oraz uruchomić symulację jeszcze raz:
- Kliknij na przycisk Parametry symulacji.
Pozwala to zapoznawać się z wynikami w oparciu o różne założenia.
Czynności
Zakładka Czynności zapewnia szczegółowe informacje dotyczące kroków procesu. Można przejść do szczegółów, aby zobaczyć, jak narastają koszty w ramach procesu oraz jak często są wykonywane poszczególne czynności.
Tabela wyników zawiera podsumowanie wszystkich czynności. Są one zgrupowane w oparciu o model i posortowane zgodnie z występowaniem w procesie. Każdy symulowany model zawiera wszystkie swoje czynności, włączając w to czynności zawarte w modelach niższego poziomu, które zostały wywołane z obiektów Podproces. Wyświetlane są następujące informacje:
Odpowiedzialne role
Liczba wykonań
Czasy
Koszty
Obciążenie
Obciążenie
Zakładka Obciążenie zawiera szczegółowe informacje potrzebne do planowania zatrudnienia. Można tam znaleźć informacje na temat liczby pracowników pełnoetatowych potrzebnych dla każdej z ról, aby proces mógł zostać wykonany w zadanym okresie.
Tabela wyników zawiera podsumowanie wszystkich Ról. Są one pogrupowane po modelu oraz posortowane alfabetycznie. Każdy symulowany model zawiera wszystkie swoje Role, włączając w to Role występujące w modelach niższego poziomu, które zostały wywołane z obiektów Podproces. Wyświetlane są następujące informacje:
Obciążenie
Czasy
Koszty
Grupowanie po rolach
Aby zgrupować wynik po Rolach:
- Wskaż nagłówek kolumny Nazwa, kliknij przycisk
 , a następnie kliknij przycisk
Grupuj po tym polu.
, a następnie kliknij przycisk
Grupuj po tym polu.
W tym widoku możesz ustalić liczbę osób potrzebnych do wykonania danej Roli.
Zdarzenia końcowe i ścieżki
Zakładka Zdarzenia końcowe i ścieżki pozwala na analizę Zdarzeń końcowych pod kątem częstotliwości występowania konkretnych rezultatów procesu. Pozwala to odpowiedzieć na następujące pytania:
Jak wiele wniosków o zatrudnienie jest akceptowanych w roku, a ile odrzucanych?
Jak wiele wniosków o przyznanie kredytu jest akceptowanych w roku, a ile odrzucanych?
Ile razy produkt nie spełnia wymagań dotyczących jakości?
Tabela wyników zawiera podsumowanie wszystkich Zdarzeń końcowych. Są one pogrupowane po modelu oraz posortowane alfabetycznie. Każdy symulowany model zawiera wszystkie swoje Zdarzenia końcowe (modele niższego poziomu nie są uwzględniane). Wyświetlane są następujące informacje:
Liczba wykonań
Prawdopodobieństwo
Czasy
Koszty
Analiza ścieżek i pokazywanie ścieżek
Aby przeanalizować szczegółowo alternatywne ścieżki przepływu procesu:
W tabeli wyników kliknij na dowolne Zdarzenie końcowe, aby otworzyć widżet "Ścieżki symulacji" po prawej stronie okna programu.
Z list znajdujących się na górze widżetu wybierz:
Proces
Zdarzenie końcowe
Okres do analizy
Wybierz okres: na proces / wyniki dla pojedynczej ścieżkiAby wyświetlić średnie wyniki na proces, wybierz na proces.
Aby wyświetlić dokładne wyniki na przebieg ścieżki, wybierz wyniki pojedynczej ścieżki.
Zostaną wyświetlone wszystkie ścieżki prowadzące do wybranego Zdarzenia końcowego. Dla każdej ze ścieżek pokazane są związane z nią czasy i koszty. Użyj opcji sortowania, aby ustalić, która ścieżka jest najważniejsza, najdłuższa, najkrótsza, najbardziej prawdopodobna, najbardziej kosztowna itp.
Pokazywanie ścieżki
Aby pokazać ścieżkę w modelu:
- Kliknij na nazwę ścieżki w wynikach.
Model zostanie otwarty w edytorze graficznym. Obiekty należące do ścieżki zostaną zaznaczone na obszarze modelowania. Numery wskazują liczbę wykonań danego kroku (przydatne przy pętlach).
Alternatywnie, możesz pokazać ścieżkę jako listę:
- Kliknij przycisk
 Pokaż
przebieg ścieżki obok łącza.
Pokaż
przebieg ścieżki obok łącza.
Sortowanie zawartości tabeli
Domyślnie, ścieżki posortowane są alfabetycznie. Aby to zmienić:
Kliknij na nagłówek kolumny, aby posortować tabelę w oparciu o jej zawartość (rosnąco).
Kliknij ponownie na nagłówek kolumny, aby odwrócić sortowanie.
Wybieranie kolumn
Aby wybrać, które kolumny wyświetlić:
Przycisk
pojawia się po
najechaniu na nagłówek kolumny tabeli. Kliknij przycisk, aby wywołać menu rozwijalne.Wskaż Kolumny, a potem wybierz pożądane kolumny.
Alternatywnie, możesz pokazać lub ukryć całe kategorie wyników:
- Aby ukryć kategorie, kliknij przyciski Ukryj czasy i Ukryj koszty. Te przyciski to przełączniki. Kliknij je ponownie, aby pokazać kategorie.
Grupowanie ścieżek
Aby zgrupować ścieżki:
- Kliknij przycisk Zgrupuj ścieżki.
Wszystkie unikalne ścieżki zostaną umieszczone w grupie Unikalne ścieżki. Oddzielne grupy (Grupa 1, Grupa 2, itp.) zawierają ścieżki, które różnią się tylko liczbą wykonań pętli, ale są identyczne pod innymi względami.
Analiza Co-jeśli dla Zdarzeń końcowych
Analiza Co-jeśli (ang. What-If) pozwala wyliczać czasy i koszty przy założeniu, że konkretne Zdarzenie końcowe zostanie osiągnięte konkretną liczbę razy. Pozwala to odpowiedzieć na następujące pytania:
- W tym roku zawarłem 700 umów. W przyszłym roku będzie to 1400. Co to oznacza, jeśli chodzi o czas i koszty?
Aby wykonać analizę Co-jeśli:
W tabeli wyników kliknij na dowolne Zdarzenie końcowe, aby otworzyć widżet "Ścieżki symulacji" po prawej stronie okna programu.
Wybierz z listy Zdarzeń końcowych to, które chcesz przeanalizować.
podaj liczbę wystąpień Zdarzenia końcowego.
Kliknij Oblicz.
Wyniki analizy Co-jeśli zostaną wyświetlone. W tabeli wyników wylistowane są ścieżki. Są zgrupowane po Zdarzeniu końcowym i posortowane alfabetycznie. Dla każdej ścieżki wyświetlane są następujące informacje:
Liczba wykonań
Prawdopodobieństwo
Czasy
Koszty
Poniżej w tabeli obciążeń możesz zobaczyć liczbę pełnoetatowych pracowników pełniących daną rolę potrzebnych do wykonania procesu, zakładając że Zdarzenie końcowe występuje określoną liczbę razy.
Na dole, w tabeli czynnik kosztotwórczy, możesz zobaczyć całkowite czasy i koszty wykonania procesu, zakładając że Zdarzenie końcowe występuje określoną liczbę razy (pierwszy wiersz) lub raz (drugi wiersz).
Zaawansowane koncepcje
Ta sekcja wyjaśnia zaawansowane metody definiowania warunków przejścia.
Ograniczenie liczby pętli
Jeśli proces zawiera pętle, można przypisać inne prawdopodobieństwa dla kolejnych przejść w ramach pętli. Pozwala to pokazać, że szansa poprawnego wykonania Zadania rośnie (lub maleje) z każdym kolejnym przejściem.
Wymagania dotyczące atrybutów
Aby zdefiniować prawdopodobieństwo ścieżki wychodzącej z Bramki wykluczającej, należy uzupełnić atrybut Warunek przejścia dla każdej z relacji Kolejny.
Warunki przejścia mogą być reprezentowane przez liczby zmiennoprzecinkowe
≥0 i≤1 (np. 0.7). Suma prawdopodobieństw wszystkich ścieżek wychodzących z bramki musi się równać 1.Dla pętli należy przypisać więcej niż jedno prawdopodobieństwo w taki sposób, aby wartości zmieniały się dla kolejnych wykonań. Do rozdzielania wartości służy ";". Symulacja zastosuje dla pierwszego przejścia przez pętlę pierwszą wartość, dla drugiego drugą i tak dalej.
Przykład
Chcesz podać, że prawdopodobieństwo odnalezienia nowych błędów podczas weryfikacji dokumentu spada dla każdej kolejnej zaktualizowanej wersji przekazanej w ramach weryfikacji:
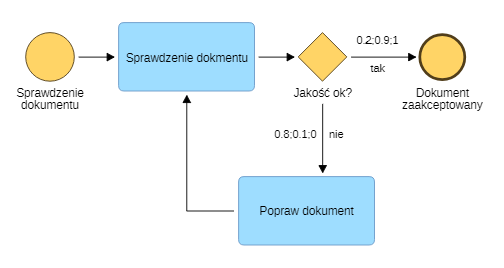
Dla pierwszego przejścia ścieżka "Jakość OK? = tak" jest wybierana w 20% przypadków, a ścieżka "Jakość OK? = nie" w 80% przypadków.
Dla drugiego przejścia ścieżka "Jakość OK? = tak" jest wybierana w 90% przypadków, a ścieżka "Jakość OK? = nie" w 10% przypadków.
Dla trzeciego przejścia i kolejnych ścieżka "Jakość OK? = tak" jest wybierana w 100% przypadków, a ścieżka "Jakość OK? = nie" w 0% przypadków.
Ustaw Warunek przejścia dla pierwszej ścieżki na "0.2;0.9", a dla drugiej na "0.8;0.1".
Wybór ścieżki procesu w oparciu o prawdopodobieństwa zależne
Powtarzające się wartości przejść można zdefiniować jako zmienne. Aby ustalić ścieżki procesu, można odwołać się do konkretnej wartości zmiennej, która zawsze dotyczy konkretnego przepływu. W ten sposób można pokazywać prawdopodobieństwa zależne.
Wymagania dotyczące atrybutów
Aby zdefiniować zmienną, wybierz relację Kolejny w procesie. Kliknij ikonę
 , żeby dodać nowy rozdział w
atrybucie Zmienne. Podaj nazwę (w pierwszej kolumnie), rodzaj rozkładu (w drugiej kolumnie)
oraz parametry rozkładu (w trzeciej kolumnie).
, żeby dodać nowy rozdział w
atrybucie Zmienne. Podaj nazwę (w pierwszej kolumnie), rodzaj rozkładu (w drugiej kolumnie)
oraz parametry rozkładu (w trzeciej kolumnie).Aby użyć zmiennej dla alternatywnych ścieżek rozpoczynających się w Bramce wykluczającej, przystosuj atrybut Warunek przejścia wychodzących relacji Kolejny. Podaj nazwę zmiennej, operatora i wartość.
Zdefiniowanie wszystkich zmiennych na początku procesu ułatwia znalezienie ich i zmianę, w razie potrzeby.
Aby dowiedzieć się więcej, kliknij na ikony informacyjne
![]() znajdujące się obok atrybutów.
znajdujące się obok atrybutów.
Przykład
Chcesz zdefiniować na potrzeby symulacji, że proces przebiega inaczej dla nowego klienta, niż dla obecnego.
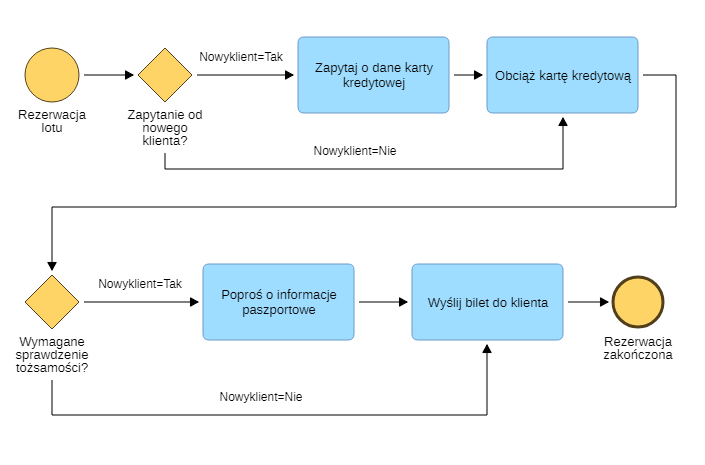
Dla pierwszej bramki ścieżka "NowyKlient = Tak" stanowi 80% przypadków, a ścieżka " NowyKlient = Nie" 20% przypadków.
Dla drugiej i każdej kolejnej bramki będą wykorzystywane te same zmienne.
Stwórz nową Zmienną z parametrami: "NowyKlient", "dyskretny", "Tak (0,8); Nie (0,2)". Ustaw Warunek przejścia wszystkich ścieżek obsługi nowego klienta na "NowyKlient = Tak", a dla ścieżek obsługi obecnego klienta na "NowyKlient = Nie".
Rozkład prawdopodobieństwa
W tym rozdziale omówimy bliżej rozkłady prawdopodobieństwa, które mogą być użyte do określenia prawdopodobieństwa alternatywnych ścieżek podczas symulacji procesu. Możliwe są poniższe rozkłady prawdopodobieństwa:
Rozkład dyskretny: W rozkładach dyskretnych każda zmienna przyjmuje stałą (dyskretną) wartość.
Rozkład ciągły: Rozkład normalny, rozkład wykładniczy i rozkład jednostajny. W rozkładach ciągłych uwaga skupiona jest na przedziale wartości, które może przyjąć zmienna.
Rozkłady prawdopodobieństwa definiowane są poprzez zmienne.
Wymagania dotyczące atrybutów
Aby zdefiniować zmienną, wybierz relację Kolejny w procesie. Otwórz notatnik i wybierz rozdział "Dane symulacyjne". Kliknij ikonę
 , żeby dodać nowy rozdział w
atrybucie Zmienne. Podaj nazwę (w pierwszej kolumnie), rodzaj rozkładu (w drugiej kolumnie)
oraz parametry rozkładu (w trzeciej kolumnie).
, żeby dodać nowy rozdział w
atrybucie Zmienne. Podaj nazwę (w pierwszej kolumnie), rodzaj rozkładu (w drugiej kolumnie)
oraz parametry rozkładu (w trzeciej kolumnie).Aby użyć zmiennej dla alternatywnych ścieżek rozpoczynających się w Bramce wykluczającej, przystosuj atrybut Warunek przejścia wychodzących relacji Kolejny. Podaj nazwę zmiennej, operatora i wartość. Dwie lub więcej zmiennych może być logicznie połączonych z użyciem operatorów AND i OR.
Rozkład dyskretny
Rozkład dyskretny ma skończoną liczbę wartości.

Zapis w systemie ADONIS
Aby zdefiniować rozkład dyskretny, wprowadź dwa lub więcej symboli wraz z odpowiadającymi im prawdopodobieństwami. Suma prawdopodobieństw musi się zawsze równać 1.
Przykładowo Variable "Zmienna X", "dyskretny", "Przebieg Normalny (0.4); Wyjątek1 (0.3); Wyjątek2 (0.3)" ma przypisaną wartość "Przebieg Normalny" z prawdopodobieństwem 40%, a wartości "Wyjątek1" i "Wyjątek2" z prawdopodobieństwem 30% każda.
Przykład
Przykład rozkładu dyskretnego znajduje się w rozdziale Wybór ścieżki procesu w oparciu o prawdopodobieństwa zależne.
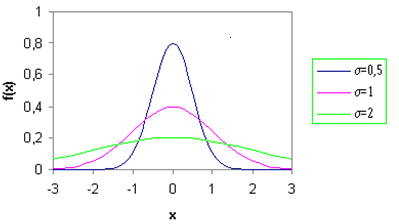
Rozkład normalny
Rozkład normalny (albo rozkład Gaussa) jest najważniejszym typem ciągłego rozkładu prawdopodobieństwa.
Zapis w systemie ADONIS
Aby zdefiniować rozkład normalny, potrzebne są dwa parametry: wartość oczekiwana i odchylenie standardowe.
Przykładowo Zmienna "Zmienna X", "normalny", "0\@2" ma rozkład normalny z oczekiwaną wartością 0 i odchyleniem standardowym 2.
Przykład
Szkody pokrywane ubezpieczeniem podlegają rozkładowi normalnemu z średnią 100 PLN i odchyleniem standardowym 20 PLN. Dla roszczeń o wysokości 90 PLN i poniżej, rozstrzyganie roszczenia jest inicjowane bezpośrednio. Roszczenia powyżej 90 PLN podlegają audytowi. Jakie jest prawdopodobieństwo, że roszczenie zostanie rozstrzygnięte bezpośrednio?
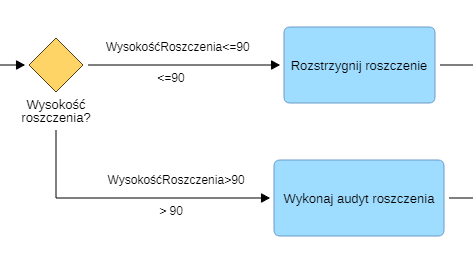
Pierwsza ścieżka wybierana jest, kiedy wysokość roszczenia jest mniejsza lub równa 90 PLN, a druga, jeżeli roszczenie jest wyższe niż 90 PLN.
Stwórz nową Zmienną "WysokośćRoszczenia", "normalny", "100\@20". Ustaw Warunek przejścia na "WysokośćRoszczenia<=90" dla pierwszej relacji Kolejny i "WysokośćRoszczenia>90" dla drugiej relacji Kolejny.

Rozkład wykładniczy
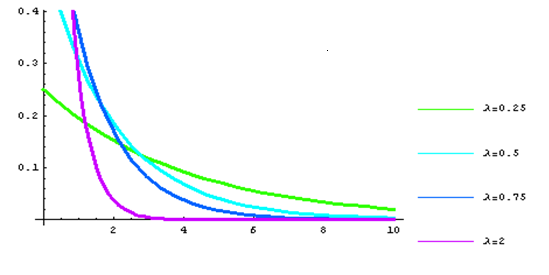
Rozkład wykładniczy jest ciągłym rozkładem prawdopodobieństwa w zbiorze dodatnich liczb rzeczywistych. Jest często używany do modelowania czasu, który upłynął pomiędzy wydarzeniami.
Zapis w systemie ADONIS
Aby zdefiniować rozkład wykładniczy, wprowadź wartość rozkładu wykładniczego, która jest ilorazem liczby 1 i wartości oczekiwanej (1/wo).
Przykładowo Zmienna "ZmiennaX", "wykładniczy", "0.5" ma rozkład wykładniczy z wartością oczekiwaną 2.
Przykład
Klienci spędzają średnio 2 minuty w kolejce w call center. Jeżeli muszą czekać dłużej niż 3 minuty, system zarządzania kolejką proponuje klientom opcję automatycznego oddzwonienia o określonej porze. Jakie jest prawdopodobieństwo, że klient będzie musiał czekać dłużej niż 3 minuty?

Pierwsza ścieżka wybierana jest, kiedy czas oczekiwania jest mniejszy lub równy 3 min, a druga ścieżka, kiedy jest większy niż 3 min.
Stwórz nową Zmienną "Czas Oczekiwania", "wykładniczy", "0.5" (1/wo = 1/2). Ustaw Warunek przejścia na "Czas Oczekiwania<=3" dla pierwszej relacji Kolejny i "Czas Oczekiwania>3" dla drugiej relacji Kolejny.

Rozkład jednostajny
Rozkład jednostajny opisuje rozkład prawdopodobieństwa, w którym wartości pomiędzy górną i dolną granicą mają takie samo prawdopodobieństwo.

Zapis w systemie ADONIS
Aby zdefiniować rozkład jednostajny, wprowadź granice rozkładu jednostajnego, gdzie pierwsza liczba jest dolną granicą, a druga liczba jest górną granicą.
Przykładowo Zmienna "Zmienna X", "jednostajny", "20\@100" ma rozkład jednostajny pomiędzy 20 a 100..
Przykład
Bank ADOMoney oferuje kredyty pomiędzy 10000 PLN a 500000 PLN. Dla kredytów powyżej 100000 PLN, muszą zostać wykonane dodatkowe zadania w przepływie procesu. Liczba kredytów w portfolio jest (w przybliżeniu) jednolita dla każdej kwoty kredytu. Jakie jest prawdopodobieństwo, że wielkość kredytu przekracza 100000 PLN?

Pierwsza ścieżka wybierana jest, kiedy wielkość kredytu jest większa lub równa 100000 PLN, a druga, jeżeli wielkość kredytu jest mniejsza niż 100000 PLN.
Stwórz nową Zmienną "Wielkość", "jednostajny", "10000\@500000". Ustaw Warunek przejścia na "Wielkość>=100000" dla pierwszej relacji Kolejny i "Wielkość<100000" dla drugiej relacji Kolejny.

Eksport wyników symulacji
Aby wyeksportować wyniki symulacji jako plik Excel (format XLSX):
- Kliknij na przycisk
 Eksportuj
wyniki .
Eksportuj
wyniki .
Arkusz Excel zawiera wyniki aktualnie otwartej zakładki.